
Searching for log monitoring tools usually means something has already gone wrong. Debugging production incidents takes too long because logs are scattered across services. Your observability bill may keep rising each month. Or your current logging setup works, but only the one engineer who built it knows how to query it.
Modern systems generate enormous amounts of logs, and without the right tooling, those logs quickly become expensive, noisy, and difficult to search.
This guide takes a more practical approach. We’ll look at the log monitoring tools teams are actually using in production, what they’re good at, what they struggle with, and how to decide which one fits your environment.
What to Evaluate Before Picking a Log Monitoring Tool
Before comparing features, answer these questions for your team:
- What’s your daily log volume? Tools priced per GB hit very differently at 10 GB/day vs. 500 GB/day.
- What are your retention requirements? Compliance mandates (HIPAA, PCI, SOC 2) may require 90 days to a year of searchable log history.
- Do your alerts fire on things that actually need attention, not noise? Effective alerting should highlight real issues rather than overwhelming teams with constant notifications.
- How easy is it to search and query logs? During incidents, engineers need to find the right log fast. Tools that offer fast full-text search, structured queries, or SQL-like languages reduce investigation time.
- What’s your team’s query fluency? Some tools require learning a proprietary query language. Others offer SQL or familiar grep-like syntax.
With these factors in mind, here are the log monitoring tools worth evaluating in 2026.
The 10 Best Log Monitoring Tools of 2026
1. Middleware
Best for: Full-stack observability teams who want logs, metrics, and traces in one platform without the Datadog bill.
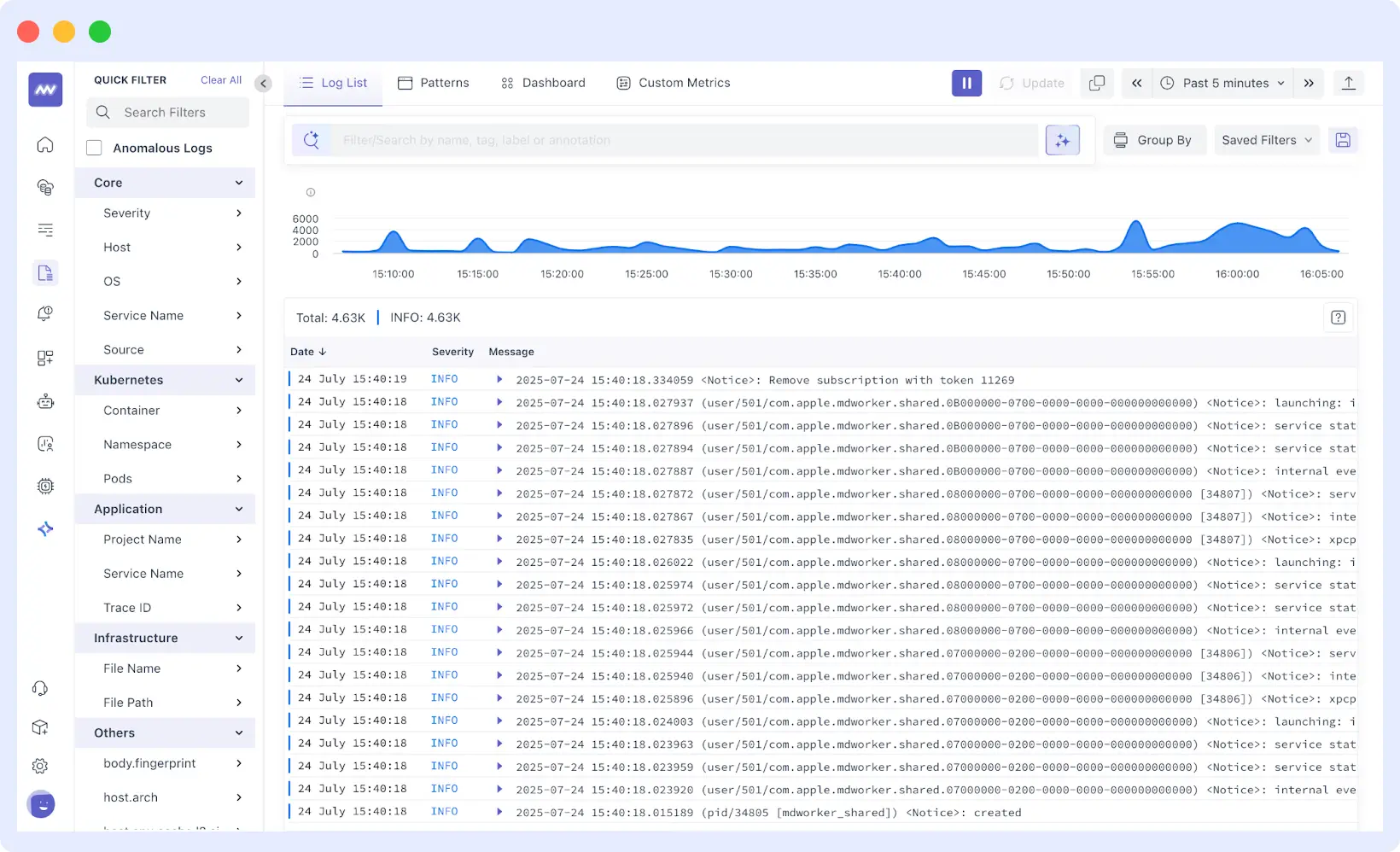
Middleware is a modern OpenTelemetry-native observability platform built by engineers who previously worked at companies like Netflix, Google, and DigitalOcean. It was designed to address a common problem in cloud-native systems, where logs, metrics, traces, and user experience data are scattered across multiple tools. Middleware brings these signals together into a single platform so engineers can move from a log event to the related trace, infrastructure metric, or user session without switching dashboards.
The platform unifies logs, metrics, traces, infrastructure monitoring, and Real User Monitoring (RUM), while also offering features such as a Log Pipeline to control ingestion costs and OpsAI, an AI agent that analyzes telemetry data, identifies root causes, and can even generate pull requests to fix issues. This makes Middleware a strong option for teams that want full-stack observability without managing multiple monitoring tools.
What stands out:
- Centralized log collection from infrastructure, containers, and application layers in a single dashboard
- Real-time log tailing with fast full-text and structured search
- AI-based anomaly detection that surfaces unusual log patterns without manual threshold configuration
- Strong Kubernetes support for pod, namespace, and label enrichment out of the box
- OpenTelemetry-native, so no vendor lock-in on the collection layer
- Role-based access controls for multi-team environments
- Cost-effective – up to 5x cheaper than comparable observability platforms
The catch: Middleware is still a relatively young platform compared to long-established observability tools vendors. While its core capabilities are solid, the ecosystem and long-term feature depth are still evolving. That said, the platform has grown quickly in a short time and is already used by enterprise customers such as Hoichoi, Walmart, Lee, and CEAT, showing strong early adoption.
Pricing:
Middleware pricing starts with a free tier with 100 GB/month ingestion. Pay-as-you-go at $0.30/GB for metrics, logs, and traces combined is significantly cheaper than Datadog or New Relic at comparable usage.
Where it’s a fit:
Middleware is best suited for teams running cloud-native applications on Kubernetes, in containers, or with microservices who need logs, metrics, and traces on a single platform. It’s a strong option for organizations looking to replace multiple monitoring tools with unified observability while keeping costs predictable as telemetry volume grows.
2. Dynatrace
Best for: Large enterprises running complex hybrid and multi-cloud environments where manual configuration doesn’t scale.
Dynatrace is an enterprise-grade observability platform built around its AI engine, Davis, which automatically discovers, maps, and monitors every component of your stack. It’s designed for large organizations running complex hybrid and multi-cloud environments where manual configuration simply doesn’t scale.
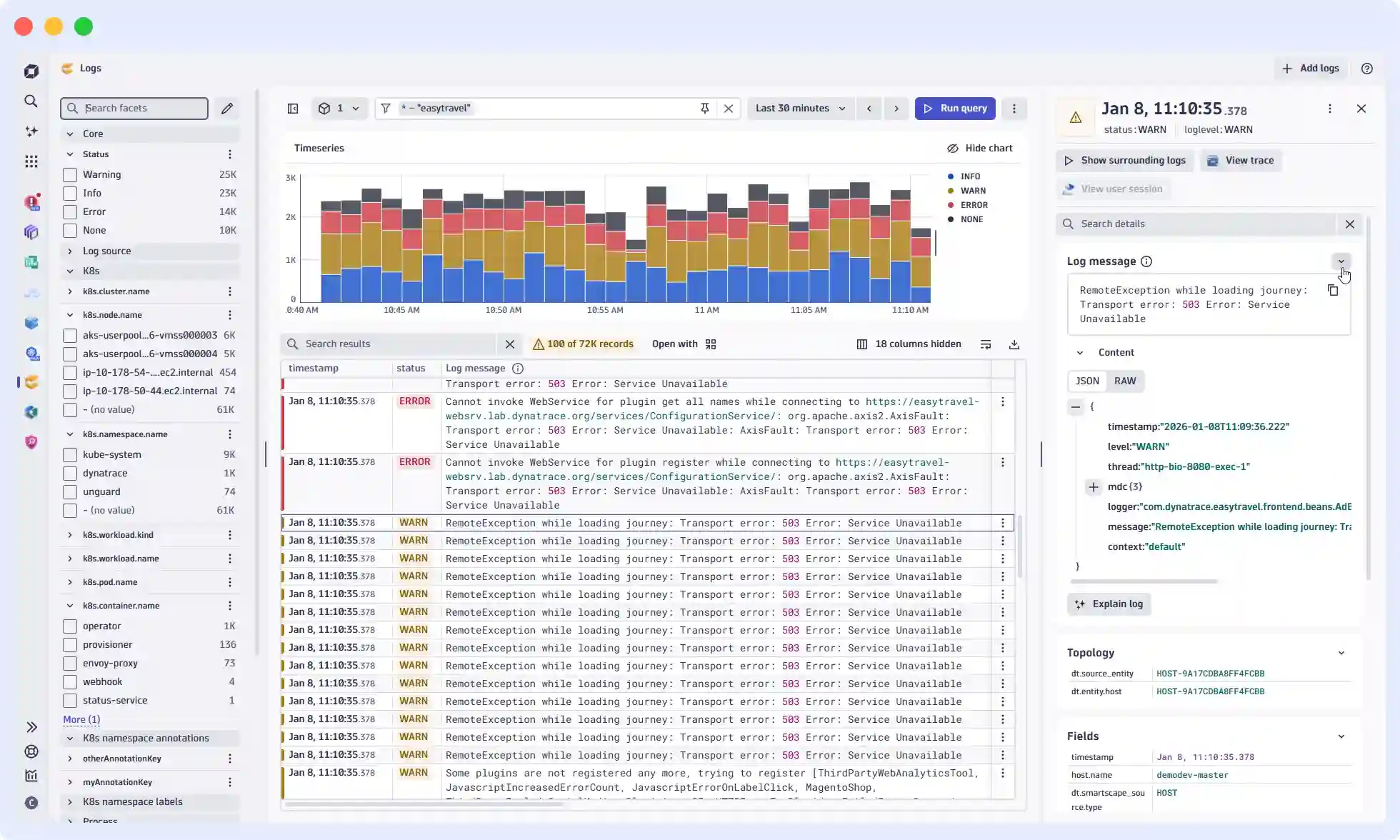
When something goes wrong, Davis doesn’t surface a hundred individual alerts. It follows the dependency chain: service A failed because service B slowed down due to a connection limit on database C, and presents a single root-cause event. For organizations with large component counts and complex interdependencies, this saves the investigation time that other tools leave on the table.
What stands out:
- Davis AI traces root cause through dependency chains automatically, not just symptoms
- OneAgent instruments the full stack without per-service configuration
- Native support for AWS, Azure, GCP, Kubernetes, and Red Hat OpenShift
- Covers logs, metrics, traces, and real user monitoring in one platform
- Auto-discovers new services and infrastructure as your environment changes
The catch: DQL (Dynatrace Query Language) is proprietary, so query expertise doesn’t transfer if you ever move on. The learning curve is real for teams coming in fresh. Pricing has three components: ingestion, retention, and querying that require careful monitoring to avoid surprises at scale.
Pricing: Log ingestion at $0.20/GiB. Retention at $0.0007/GiB per day. Querying at $0.0035/GiB.
See how Middleware and Dynatrace differ on pricing and setup: Middleware vs Dynatrace →
3. New Relic
Best for: Teams that want a single platform with predictable per-user pricing.
New Relic’s approach is built around a unified telemetry pipeline that logs metrics, events, and traces, all of which flow into the same data store and are queryable via NRQL (New Relic Query Language). Log management integrates tightly with APM and infrastructure monitoring, which makes cross-signal investigation practical.
What stands out:
- Unified data model across logs, metrics, traces, and events
- NRQL is SQL-like and relatively easy to learn
- Strong live-tail functionality for real-time debugging
- Log patterns feature automatically group similar log entries to reduce noise
- 100 GB free data ingestion per month
The catch: Pricing beyond the free tier can get expensive, particularly for organizations with many full-platform users. The query language, while approachable, is proprietary.
Pricing: New Relic pricing starts with a free tier of 100 GB/month. Standard starts at $10/user. Data ingestion beyond the free tier costs $0.35/GB.
Also read: Middleware vs New Relic →
4. Datadog
Best for: Large enterprises with complex environments and a budget to match.
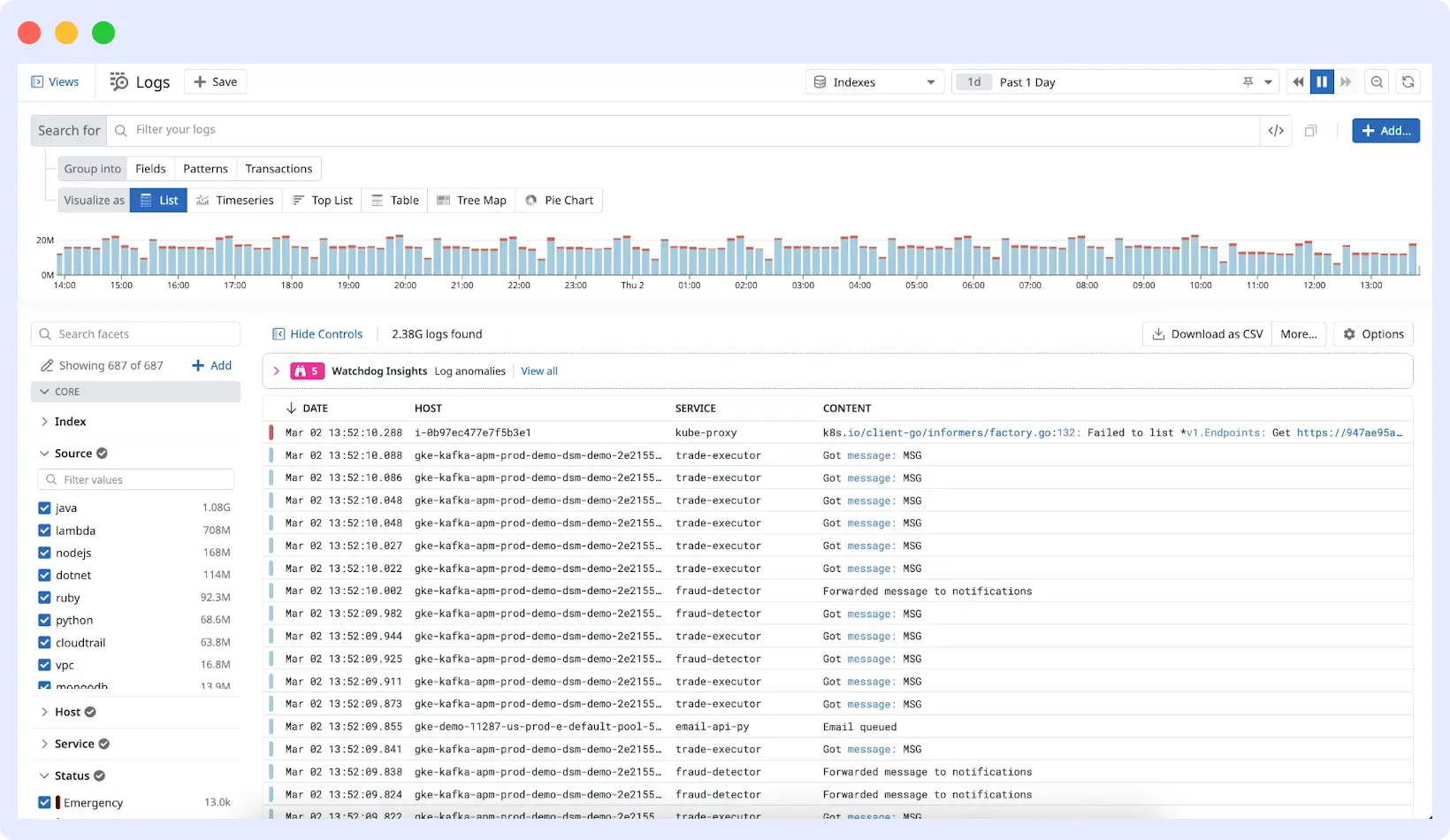
Datadog is the incumbent in the observability market for good reason. Its log management product is mature, deeply integrated with the rest of the Datadog platform (metrics, APM, synthetic monitoring, security), and has an extensive library of integrations. Its Log Explorer is powerful, and the ability to correlate logs directly with APM traces is genuinely useful.
What stands out:
- 500+ integrations for log collection and parsing pipelines
- Log-to-trace correlation is seamless within the platform
- Powerful log processing pipelines for normalization and enrichment
- Security monitoring (SIEM) is built into the same platform
- Excellent dashboarding and visualization
The catch: Datadog’s pricing model is notoriously complex and expensive at scale. Log management is priced separately from infrastructure monitoring and APM. At high log volumes, costs compound quickly, and many teams find themselves managing what they ingest just to avoid bill shock.
Pricing: $0.10/GB ingestion + $1.70/GB for 15-day indexing. Custom enterprise pricing available.
Datadog Getting Expensive? See how Middleware compares with DataDog Middleware Vs DataDog
5. Splunk
Best for: Large enterprises with security-heavy use cases and existing Splunk investment.
Splunk built its reputation on indexing and searching machine data at scale. Its Search Processing Language (SPL) is genuinely powerful, not just marketing-speak, and its SIEM capabilities make it a common choice in security operations. If your log monitoring use case overlaps significantly with security event analysis, Splunk is worth serious consideration.
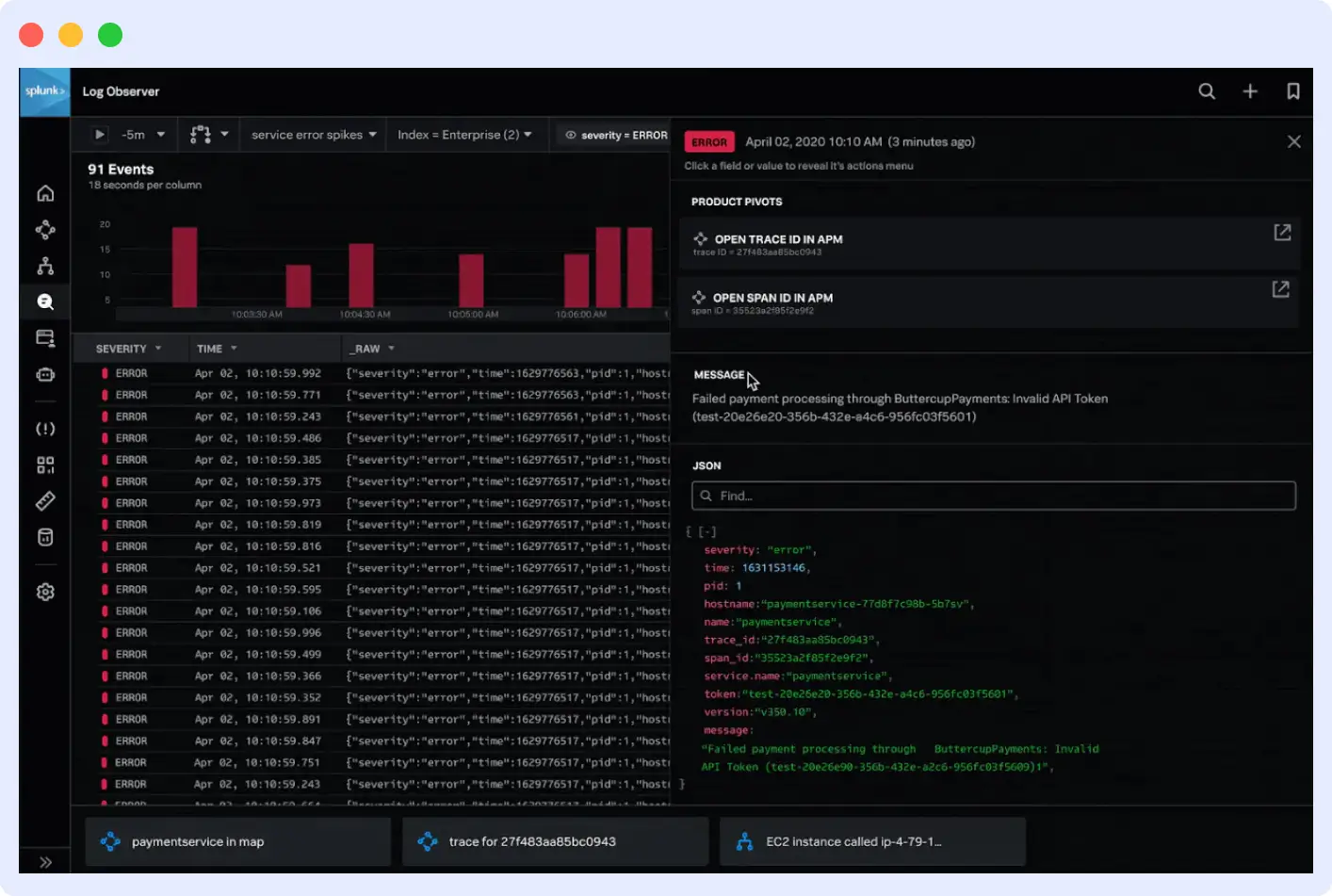
What stands out:
- SPL is extremely capable for complex log analysis and correlation
- Industry-leading SIEM and security analytics
- Handles unstructured and multi-line logs well
- Strong compliance and audit trail capabilities
- Large ecosystem of apps and add-ons
The catch: Splunk’s cost model, traditionally priced by daily ingest volume, is expensive at scale. It requires meaningful operational overhead to deploy and maintain. The learning curve for SPL is real.
Pricing: Free tier at 500 MB/day. Enterprise pricing starts around $225/month for 100 GB/day, though most large deployments involve custom enterprise contracts.
6. Grafana Loki
Best for: Teams already invested in the Grafana stack who want cost-effective log storage.
Loki takes a deliberately different approach to log storage: rather than indexing log content (like Elasticsearch does), it only indexes metadata labels. Log data is stored as compressed chunks. This makes Loki significantly cheaper to operate at scale, but it means full-text search across log content is slower and more expensive in terms of query time.
What stands out:
- Very low storage cost compared to Elasticsearch-based solutions
- Native integration with the dashboard of Grafana and Prometheus
- LogQL query language is concise and aligns with PromQL
- Excellent fit for Kubernetes environments using the Promtail or Alloy agents
- Open-source with self-hosted or Grafana Cloud-managed options
The catch: Full-text search performance degrades as scale increases. If your team needs to search across large log volumes without knowing the label structure in advance, Loki can be frustrating. It rewards teams with well-defined, consistent labeling practices.
Pricing: Open-source (self-hosted, free). Grafana Cloud includes a generous free tier; paid tiers start at $0.50/GB ingested.
7. Elastic (ELK Stack)
Best for: Teams with the engineering capacity to operate a self-managed stack and need maximum customization.
The Elastic Stack, Elasticsearch, Logstash, and Kibana have been the default choice for self-managed log infrastructure for over a decade. Kibana’s log viewer and Discover interface are mature and flexible. Elasticsearch’s full-text search is fast and well-understood.
What stands out:
- Powerful full-text and structured search via Elasticsearch
- Kibana provides rich dashboarding and visualization
- Beats agents (Filebeat, Metricbeat) are lightweight and battle-tested
- Highly customizable can be tailored to almost any logging architecture
- Large community and extensive documentation
The catch: Operating Elasticsearch at scale requires real infrastructure expertise. Cluster management, index lifecycle policies, shard sizing, and performance tuning are non-trivial. The managed Elastic Cloud offering reduces this burden but increases cost.
Pricing: Open-source (self-hosted). Elastic Cloud managed service starts at around $95/month; pricing scales with storage and compute.
8. Mezmo
Best for: Teams dealing with high log volumes who want to control what reaches storage and reduce both noise and cost at the collection layer.
Mezmo gives teams control over their log data before it ever reaches storage. By letting you parse, filter, enrich, and route logs at the pipeline level, it reduces noise, cuts ingestion costs, and ensures only the right data reaches the right destination. A major advantage for teams dealing with high-volume, distributed log streams.
Pros
- Fast real-time log tailing and filtering across distributed log streams
- Quotas and index rate alerting to monitor and control unexpected data spikes
- Granular notifications triggered by specific searches, correlations, and storage criteria
- Auto and custom parsing and enrichment to structure logs into a more usable format
- Powerful telemetry pipeline to route the right log data to the right destination
- Intuitive UI with strong Kubernetes and cloud-native integrations
Cons
- Costs can grow significantly at high log volumes
- Metrics and traces support is less mature than dedicated platforms
- Navigation can feel cumbersome for complex queries
Pricing: Free community plan with no data retention. Professional at $0.80/GB with 3-day retention. Enterprise is custom.
9. GoAccess
Best for: Developers and small teams who need fast, zero-overhead visibility into web server traffic without the complexity of a full observability platform.
GoAccess is a single-purpose tool. It analyzes web server logs, Apache, Nginx, Amazon S3 access logs, Cloudfront, and several others, and it does it in real time, directly in a terminal or a browser dashboard, with millisecond refresh rates.
For developers running personal projects, small teams managing a handful of web servers, or anyone who needs quick visibility into traffic patterns without standing up infrastructure, this is the fastest path from zero to useful information.
The limitations are equally clear: no alerting, no long-term retention, no distributed system support, no application-level logs.
Pros
- Real-time web server log analysis with millisecond-level data refresh
- Runs in terminal or browser with zero external dependencies or infrastructure
- Incremental log processing reads only new entries, not the entire file each time
- Supports Apache, Nginx, Amazon S3, Cloudfront, and more without configuration
- Completely free with no infrastructure cost or licensing
Cons
- Limited to web server log formats, not suitable for application or infrastructure monitoring
- No alerting, anomaly detection, or long-term log retention
- Does not scale to distributed or multi-service environments
Pricing: Free and open-source.
10. Graylog
Best for: Mid-size teams that want open-source log management with a reasonable UI.
Graylog sits between the full complexity of the ELK stack and the simplicity of hosted solutions. It uses Elasticsearch or OpenSearch as a backend but wraps it in a more opinionated, operator-friendly interface. Alert management, role-based access, and compliance-focused audit features are well-developed.
What stands out:
- Cleaner operator experience than raw Kibana for log management workflows
- Strong alerting and notification pipeline
- GELF (Graylog Extended Log Format) supports rich structured log data
- Good compliance and access control features
- Active open-source community
The catch: It still requires Elasticsearch/OpenSearch to operate underneath it, so the operational complexity of that dependency doesn’t fully disappear.
Pricing: Open-source. Enterprise edition starts at $1,250/month.
How to Choose a Log Monitoring Tool
| Best for | Pricing | |
| Middleware | Unified logs, metrics & traces at a fraction of competitor costs | Free (100 GB/mo); $0.30/GB after |
| Dynatrace | AI-driven root cause analysis with auto-discovery across complex enterprise stacks | $0.20/GiB ingestion; $0.0007/day retention |
| New Relic | Correlating logs, metrics & traces in a single platform with a generous free tier | Free (100 GB/mo); $0.35/GB after |
| Datadog | Real-time log analysis with 500+ integrations and powerful ML-based anomaly detection | $0.10/GB ingestion + $1.70/million log events/mo |
| Splunk | Powerful SPL-based search & analytics built for enterprise security and compliance | Quote-based (contact sales) |
| Grafana Loki | Cost-efficient log storage for Grafana/Prometheus stacks | Open-source; Grafana Cloud paid tiers |
| Elastic (ELK Stack) | Customizable self-managed logging infrastructure | Open-source; Elastic Cloud paid |
| Mezmo | Parsing, enriching & routing high-volume log pipelines before they hit storage | Free (no retention); $0.80/GB with 3-day retention |
| GoAccess | Instant real-time web server log analysis with zero setup and no infrastructure | Free (open-source) |
| Graylog | Centralized log management with flexible self-hosted or cloud deployment options | Free (self-hosted); from $1,250/mo (cloud) |
Start with the observability scope. If you only need logs, Loki or Graylog can be cost-effective. If you need logs alongside metrics and traces, a unified platform like Middleware or Datadog reduces the operational overhead of stitching together multiple tools.
Run the math at your actual log volume. Most tools offer free trials. Ingest a week of real production logs, measure the cost, and project forward at 2x growth. Surprises at this stage are much cheaper than surprises at renewal.
Test the query experience under realistic conditions. The best UI in the world doesn’t matter if queries on 30-day windows time out. Test with the volume and time ranges your team actually uses in incidents.
Factor in operational overhead. Hosted SaaS tools trade money for engineering time. Self-managed tools (Loki, Elastic, Graylog) trade money for operational complexity. That trade-off is different for a three-person platform team vs. a dedicated SRE org.
The right log monitoring tool is the one your team will actually use consistently, in incidents, at 3 AM. Optimize for that.
If you’re ready to test one, Middleware is free to start, no credit card needed. Get started →



